Cet article cherche à montrer comment l’architecture logique, en tant que discipline, contribue à la maîtrise des systèmes informatiques. Après quelques rappels sur les règles de cette discipline, il calcule l’impact de ces règles sur la complexité.
Les règles de l’architecture logique
L’architecture logique, en tant que produit, est la structure du système informatique (plus généralement : du système technique), sans le détail des dispositifs techniques. Puisque son objet est un système artificiel, nous pouvons imposer, à cette architecture, des règles structurelles ou contraintes topologiques, dans le but de mieux maîtriser le système. Les plus largement admises sont les suivantes :
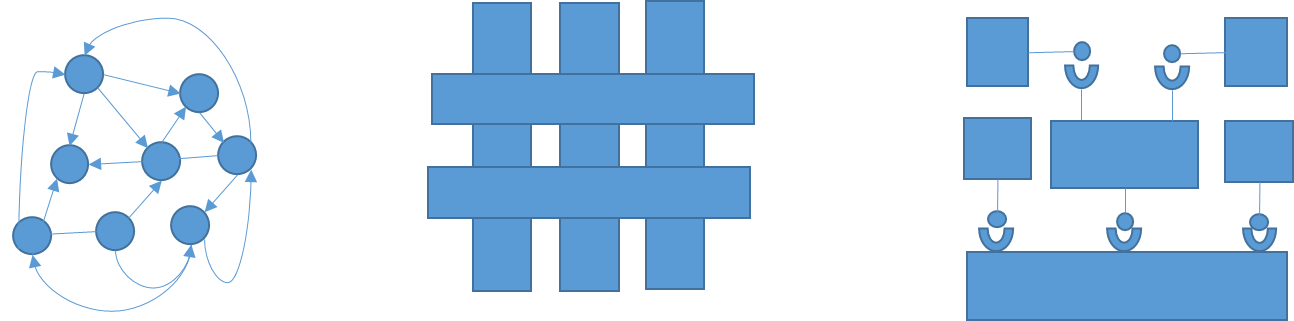
- Prohibition des relations mutuelles : entre deux constituants, il ne peut exister qu’une dépendance, au plus (autrement formulé : les relations entre les constituants sont unidirectionnelles).
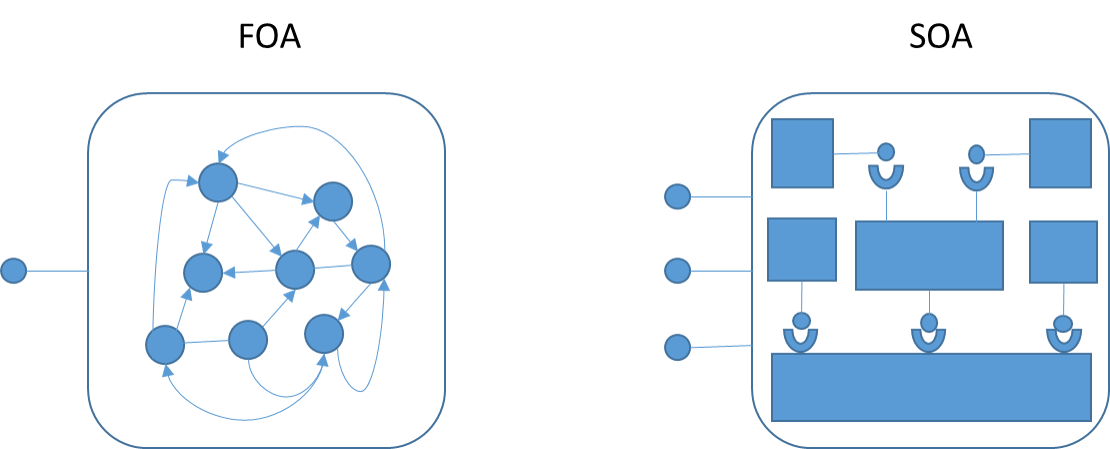
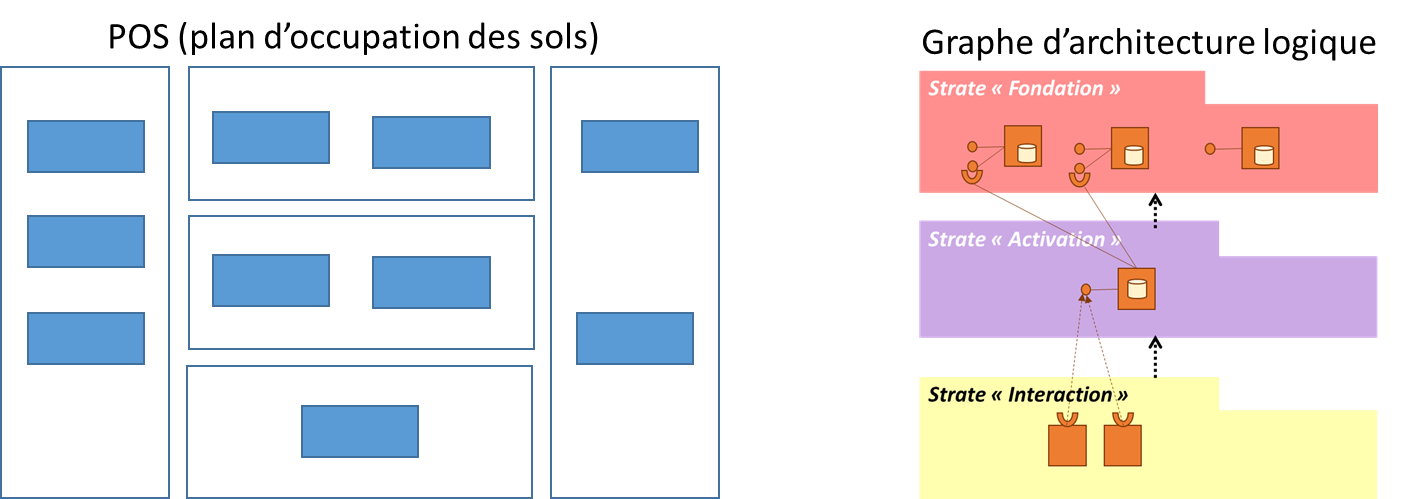
- Stratification (ou architecture en couches) : le système se compose de plusieurs couches ; la communication entre les couches est polarisée. Plus précisément, dans l’approche préconisée par Praxeme, l’architecture logique comprend : une strate « Fondation » qui dérive de l’aspect sémantique (les objets « métier »), une strate « Activation » qui dérive de l’aspect pragmatique (les activités « métier ») et une strate « Interaction », abstraction des composants d’interaction (IHM et communication avec d’autres systèmes). Les seules communications autorisées entre strates vont des constituants de la strate « Interaction » vers ceux de la strate « Activation » et de ces derniers vers la strate « Fondation ». Toutes les autres communications sont prohibées.
- Prohibition des relations latérales dans la strate « Activation » : les blocs correspondant aux domaines fonctionnels n’entretiennent pas de relations ; ils s’échangent de l’information uniquement à travers la strate « Fondation », le noyau du système. Cette règle résulte de l’importance accordée aux référentiels d’objets dans l’architecture. Ceux-ci, traduisant les domaines d’objets trouvés dans l’aspect sémantique, sont placés dans la strate « Fondation ».
- Règle de médiatisation : un composant d’interaction échange avec un et un seul composant d’activation principal. Il peut solliciter aussi les services de composants utilitaires ou généraux. Pour un composant d’activation, on peut avoir plusieurs composants d’interaction, un par type de technologie de dialogue.
Cette architecture tolère quelques – rares – dérogations, notamment en ce qui concerne les services utilitaires qui, par construction, doivent avoir une position « transverse ». Mais ces dérogations sont marginales et ne changent pas le raisonnement qui suit, pour le calcul de la complexité.
L’impact sur la complexité du système
Il est facile de montrer comment ces règles d’architecture logique réduisent considérablement la complication du système.
Soit n le nombre d’éléments d’un système. Le nombre maximum de dépendances que l’on peut instaurer entre ces éléments est n².
La prohibition des relations mutuelles réduit ce nombre de moitié.
Le principe de stratification va plus loin. Soient nf, na, ni, les nombres d’éléments de chacune des strates. On a : n = nf + na + ni.
À partir de là, il reste à calculer le nombre maximal de dépendances, autorisé par les contraintes topologiques.
Dans la strate « Fondation », le nombre de dépendances possibles est nf²/2. Les constituants de cette strate ne communiquent pas vers les autres strates.
Dans la strate « Activation », les constituants n’échangent pas entre eux mais « orchestrent » les services de la strate « Fondation ». Au maximum (si chaque constituant d’activation appelle tous les constituants de fondation), le nombre de dépendances est donc : nf. na.
Enfin, les constituants d’interaction ne sont liés qu’à un constituant d’activation. Ceci conduit à ajouter uniquement ni dépendances.
Le raisonnement laisse de côté quelques détails (dérogations, services utilitaires) qui ne changent pas fondamentalement le résultat.
Le simple respect des règles d’architecture logique abaisse donc le nombre de dépendances d’un système de
(nf + na + ni) ²
à
(nf²/2 + nf. na + ni).
La différence est considérable. Si on se place dans le contexte d’un système SOA (service oriented architecture), le nombre de constituants en jeu est de l’ordre de la centaine ou du millier. Pour donner une idée, imaginons un système plutôt simple où nf = na = ni = 100. Sans appliquer les contraintes topologiques, le nombre de dépendances permises est : 90.000. En appliquant les règles, ce nombre tombe à 1.600. Encore n’est-ce là que la valeur maximale autorisée. En réalité, les décisions d’architecture logique vont encore diminuer ce nombre. Par exemple, le « principe de confiance » peut entraîner une réduction de moitié du nombre de dépendances dans la strate « Fondation », en amenant en plus à augmenter l’autonomie des constituants.
La mesure du nombre de dépendances n’est sans doute pas une mesure directe de la complexité mais elle en donne une idée. Elle révèle surtout le couplage, lequel est un des facteurs évidents de la complexité des systèmes artificiels. Notre propos, ici, n’est pas d’élaborer une mesure de la complexité (voir, par exemple, l’article coécrit par Yves Caseau, Daniel Krob et Sylvain Peyronnet), mais de faire sentir l’enjeu d’une vraie pratique d’architecture logique.
Le rôle de l’architecture logique
Ce raisonnement peut paraître théorique. Il ne l’est pas quand l’architecture logique peut réellement s’exercer, et que l’effort de conception permet de reprendre en main le système. Dans les autres cas, on pourrait se dire que la situation n’est pas si critique, que les quelques dizaines d’applications ne peuvent engendrer de tels niveaux de complexité et que le nombre de connexions observées dans le système existant (disons quelques centaines) reste bien inférieur aux nombres évoqués ci-dessus, donc qu’il n’y a pas péril en la demeure. Soyons clairs : c’est faux ! Dans un système constitué d’applications monolithiques, la complexité est cachée. Ce n’est pas parce qu’elle ne se révèle pas à travers les dépendances visibles qu’elle n’existe pas. Dans ces systèmes, la non-application du principe de stratification entraîne une redondance énorme. Cette redondance est une source de complication et un risque effroyable. Elle finit par paralyser les évolutions de nos systèmes, et mobilise des ressources considérables pour une valeur faible.